SELECT SELECT 문은 데이터베이스에서 데이터를 선택하는 데 사용된다. 리턴 된 데이터는 result-set라고하는 result table에 저장된다. 여기에서 column1, column2, …는 데이터를 선택할 테이블의 필드(column)의 이름이다.
SELECT
SELECT 문은 데이터베이스에서 데이터를 선택하는 데 사용된다. 리턴 된 데이터는 result-set라고하는 result table에 저장된다. 여기에서 column1, column2, …는 데이터를 선택할 테이블의 필드(column)의 이름이다.
SELECT column1, column2 FROM table_name;
테이블의 모든 필드를 선택하려면 *를 사용해서 접근한다.
SELECT * FROM table_name;
SELECT DISTINCT
SELECT DISTINCT 문은 주어진 필드의 이름에서 중복된 row를 제외한 데이터를 가져온다.
SELECT DISTINCT column1 FROM table_name;
주어진 필드의 이름 column1에서 중복된 2개 이상의 값이 있으면 하나의 record로 인식하여 제거하고 보여준다.
User 테이블
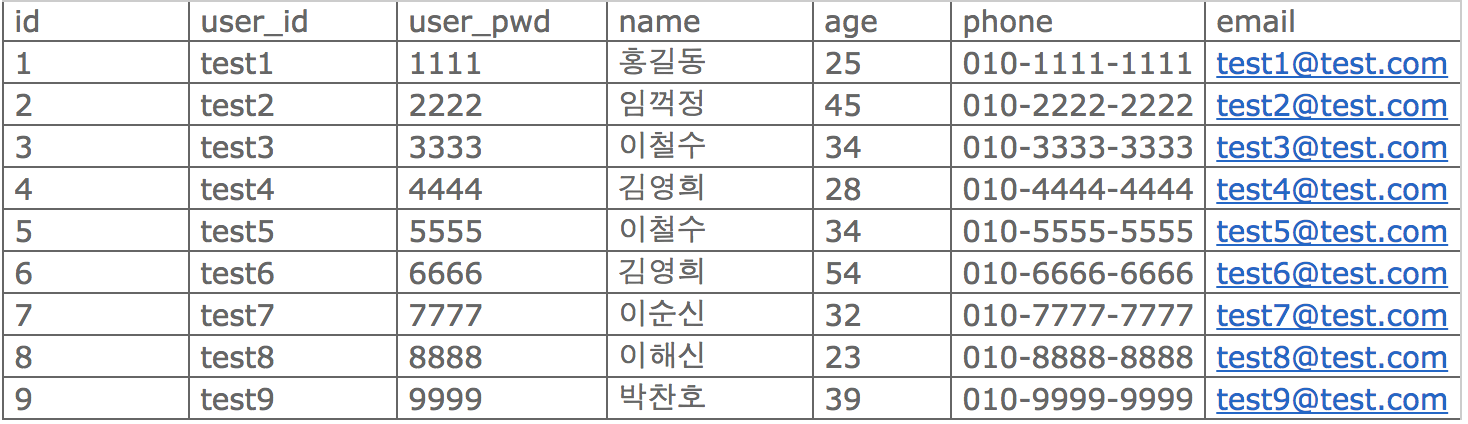
이미지 출처 - http://makand.tistory.com
이 user 테이블에 대해서 중복을 제거한 값을 가져와보자.
SELECT DISTINCT name FROM User;
출력결과
김영희
박찬호
이순신
이철수
이해신
임꺽정
홍길동
WHERE
WHERE 문은 SELECT 문에 조건을 줄 수 있다. User테이블에서 id값이 3이하인 값만 검색하고 싶다면 이렇게 sql문을 작성하면 된다.
SELECT * FROM WHERE User id <= 3;
AND
WHERE절의 키워드로 AND를 기준으로 양 옆의 조건이 모두 만족할 경우를 의미한다.
SELECT * FROM User WHERE age=34 AND user_pwd=3333;
OR
WHERE절의 키워드로 OR를 기준으로 양 옆의 조건 중 하나라도 만족 할 경우를 의미한다.
SELECT * FROM User WHERE user_id=test1 OR user_id=test3;
AND나 OR과 같은 조건쿼리문은 여러번 기술해줌으로써 조건을 다양하게 표현할 수 있다.
SELECT user_id, user_pwd FROM User WHERE (id<5 AND age<30) OR (id=9 AND age<30)
NOT
WHERE 절의 키워드로 조건을 부정할 때 사용한다.
SELECT * FROM WHERE NOT id=8;
ORDER BY
SELECT문으로 검색된 데이터를 오름차순(ASC)이나 내림차순(DESC)으로 정렬 시킬 때 사용한다. Default값은 Ascending(오름차순)으로써 ASC는 생략해도 되며, 문자는 알파벳 순서로 출력된다. ORDER BY절에 선택된 컬럼이 여러 개일 경우 앞(왼쪽)에 정의된 컬럼을 기준으로 먼저 분류한 후, 이후에 나열된 순서대로 분류한다.
emp 테이블
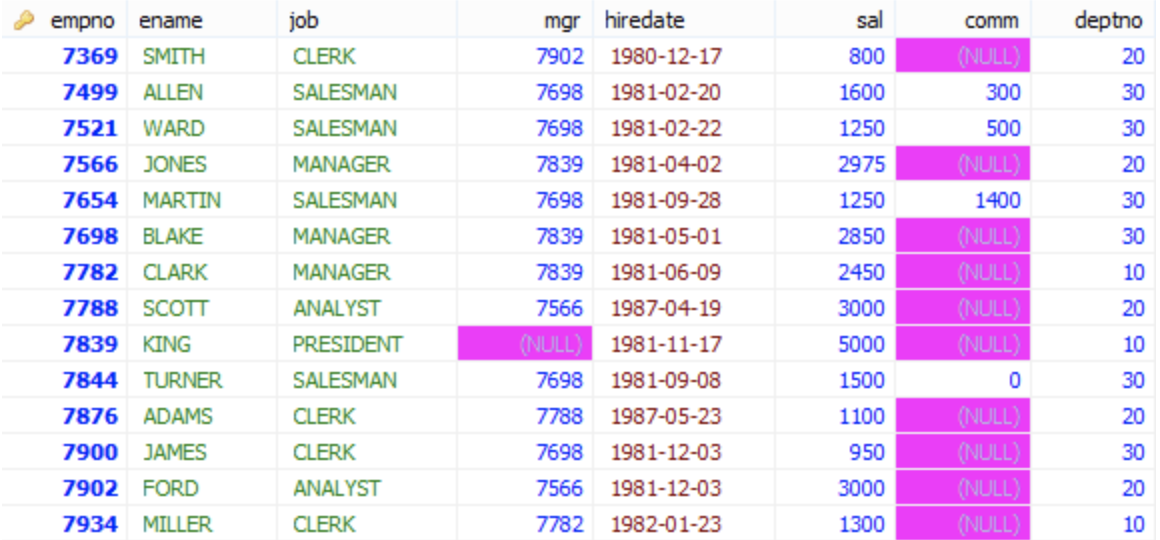
이미지 출처 - http://shaeod.tistory.com
내림차순 정렬(DESC)
SELECT empno FROM emp ORDER BY empno DESC
오름차순 정렬(ASC)
SELECT empno FROM emp ORDER BY empno ASC <- ASC 생략 가능. 다시쓰면 아래와 같다.
SELECT empno FROM emp ORDER BY empno
ORDER BY절에 지정된 컬럼이 SELECT절에 지정되지 않아도 무관하다.
SELECT job FROM emp ORDER BY empno
INSERT INTO
INSERT INTO 문은 테이블에 새 레코드를 삽입하는 데 사용된다. 테이블에 데이터를 입력하는 유형은 두 가지가 있으며 한 번에 한 건만 입력된다.
PLAYER 테이블에 값을 입력한다고 해보자.
INSERT INTO 테이블명 (COLUMN_LIST)
VALUES (COLUMN_LIST에 넣을 VALUE_LIST);
INSERT INTO PLAYER (PLAYER_ID, PLAYER_NAME, TEAM_ID, POSITION, HEIGHT, WEIGHT, BACK_NO)
VALUES ('2002007', ' 박지성', 'K07', 'MF' ,178, 73, 7);
INSERT INTO 테이블명
VALUES (전체 COLUMN에 넣을 VALUE_LIST);
INSERT INTO PLAYER
VALUES ('2002007', ' 박지성', 'K07', 'MF' ,178, 73, 7);
출처: http://hyeonstorage.tistory.com/294
해당 컬럼의 데이터 유형이 CHAR이거나 VARCHAR 등 문자열일 경우 따옴표(‘)를 값의 양 옆에 붙여준다. 숫자일 경우 숫자만 입력한다. 첫번째 방식은 입력할 데이터의 컬럼명과 입력되어야 하는 값을 1:1로 매핑하여 입력한다. 테이블 명 뒤 () 안에 입력할 테이블의 컬럼을 정의하며, 컬럼의 순서는 테이블의 실제 컬럼 순서와 매치할 필요는 없다. 여기에 정의하지 않은 컬럼은 데이터 INSERT 시에 Default로 NULL이 입력된다. 단, Primary Key 나 Not NULL 의 경우는 데이터를 항상 입력해줘야 한다.
두번째 방식 은 모든 컬럼에 데이터를 입력하는 경우로 굳이 COLUMN_LIST를 입력하지 않아도 되지만, 컬럼의 순서대로 빠짐없이 데이터가 입력되어야 한다.
얼핏 봤을 때는, 그 많은 컬럼을 다 나열하느니 두번째 방식을 사용하는게 편할 수 있지만, 시스템을 운영하다가 컬럼이 추가되는 경우에 두번째 방식의 쿼리에서 에러가 발생한다.
조금 귀찮더라도 첫번째 방식을 사용하는게 좋다.
